Google Cloud、フォーミュラ E、McKinsey QuantumBlack は共同で、そのようなエクスペリエンスを開発しました。フォーミュラ E は、レースや車両のテレメトリー データと Google Cloud の生成 AI を組み合わせたことで、ドライバーが幅広い分野について具体的に質問できる会話型インターフェースを提供できるようになりました。たとえば、「ターン 1 の脱出速度は?」といった質問を直接尋ねると、シンプルなテキストベースのインターフェースで回答が返ってきます。これまでのように、データ コーパスを手動で分析して重要な特徴量を特定し、この情報を提供する BI ダッシュボードを手動で作成してメンテナンスする必要はありません。
最新のレースカーは多数のセンサーで膨大な量のテレメトリー データを生成します。車両を最適にチューニングしてラップタイムを縮めるには、最初にレーストラックの特定のポイントで車両がどのような挙動をしたのか正確に把握することが重要です。フォーミュラ E 2023 チャンピオンシップの最終週には、次世代 GENBETA レースカーで屋内走行速度のギネス世界記録を樹立することに成功したほか、シーズンの最終チャンピオンシップ レースも 2 レース開催されました。
この週に、フォーミュラ E は大きく異なる 2 種類のペルソナに情報を提供したいと考えていました。
- 速度記録への挑戦でタイムをさらに縮めるために、自車がどのように挙動したのか確認したいドライバー
- フォーミュラ E や、現在と過去のチャンピオンシップの結果とレースデータ、次世代 GENBETA レースカーについて詳しく知りたいファン
そこで、テキストとチャットに合わせて最適化された PaLM 大規模言語モデル(LLM)と Google Cloud の Vertex AI ポートフォリオに含まれるその他の AI サービスを活用し、これら両方のユースケースとペルソナに対応した生成 AI チャット インターフェースを構築して、イベント期間中にドライバーとファンが利用できるようにしました。
デザインの概要
大まかに言えば、このシステムは、質問を処理するエージェントとして機能するカスタム バックエンド サービスと、McKinsey QuantumBlack と共同開発したフロントエンド UI で構成されています。これら 2 つのサービスはコンテナ化されており、Terraform、Cloud Build、Anthos Configuration Management(Config Sync)で構築した CI / CD パイプラインを通じて Google Kubernetes Engine に Kubernetes Deployment としてデプロイされています。フロントエンドは Identity-Aware Proxy による認証で保護されており、Cloud CDN と Cloud Storage で構築された CDN も使用しています。
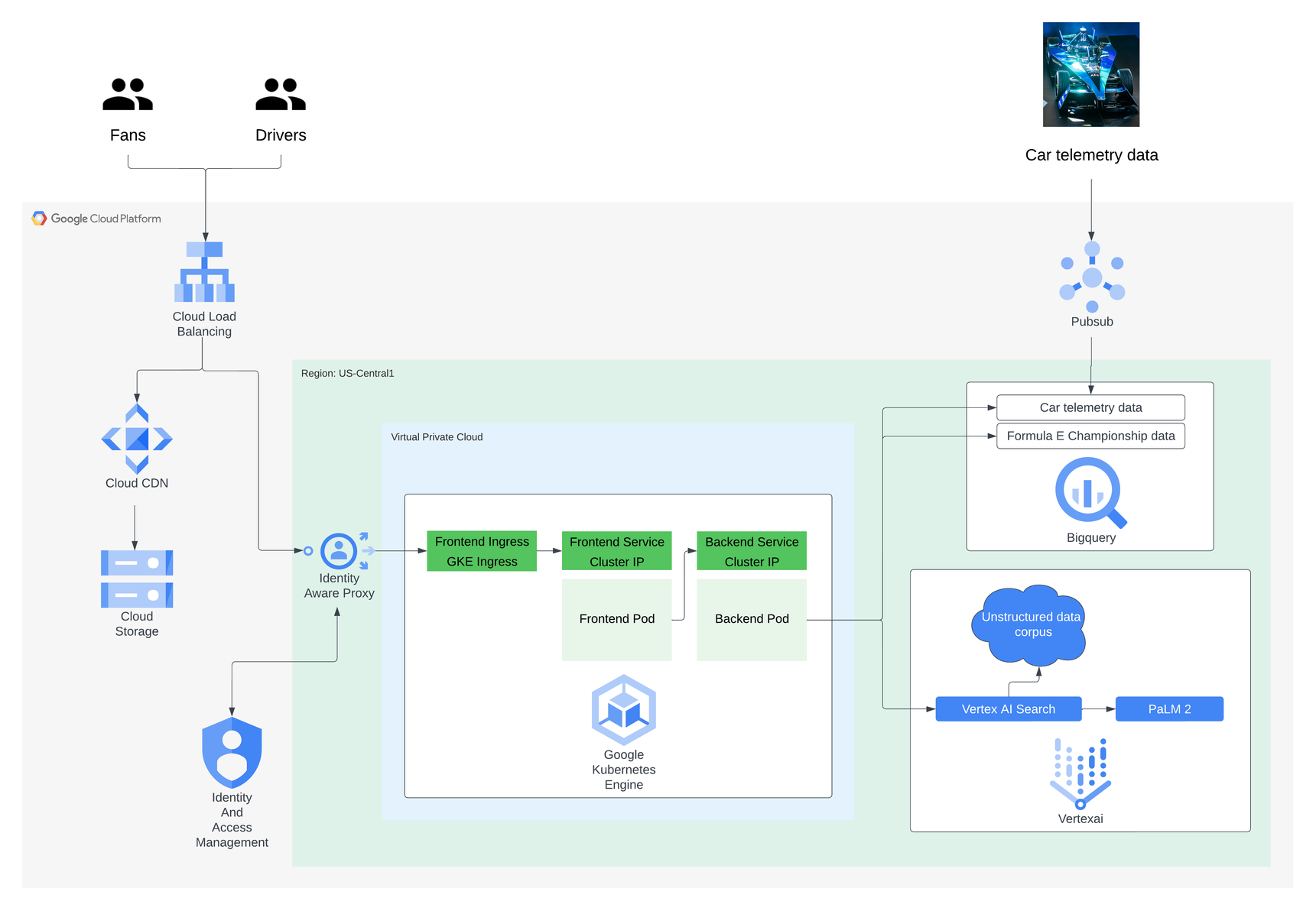
- 車両のテレメトリー データや過去のチャンピオンシップの結果といった構造化データ
- フォーミュラ E に関する一般的な情報や、フォーミュラ E と他のモータースポーツの違いを明確にするための情報といった非構造化テキスト コーパス
BigQuery、Vertex AI、Langchain を組み合わせて活用し、構造化データからコンテキストを追加
フォーミュラ E はドライバーとファン双方にとって非常に意義のある構造化データを多く保有しているため、この追加データをレスポンスに取り入れたいと考えていました。たとえば、過去や現在のチャンピオンシップのレース結果や出場資格タイムなどのデータのほか、レースカーに張り巡らされたセンサーから得られる非常に詳細なテレメトリー データなどです。バックエンド サービスからこの情報にアクセスし、データから得られたインサイトを使ってレスポンスを充実させることができるようにするための最初のステップは、まずこのデータを BigQuery に一括アップロードしてストリーミングすることでした。
次のステップは、バックエンドから、基盤モデルのトレーニング セットの外部にあるこれらのデータセットに対してクエリを動的に実行し、ユーザーの質問により正確に回答するために必要な追加情報を取得することでした。LangChain は言語モデル用のオープンソース フレームワークであり、入力された質問に基づいて SQL を動的に生成する仕組みが搭載されています。データ自体をファインチューニングするのではなく、必要なのはプロンプト調整によるコーチングだけです。Langchain と Google が Vertex AI で提供しているテキスト用の PaLM 2 API を組み合わせて利用することで、バックエンド サービスは構造化データセットからの追加データが必要になりそうな質問をまず特定できるようになります。その後、質問に回答してフロントエンドに返すために必要な関連データを、関連する BigQuery テーブルから取得する SQL クエリが動的に生成されます。
たとえば、「2018 年シーズンにローマで開催されたレースの優勝者は?」という質問は、基盤モデルのトレーニング セットの外部にある質問として識別され、レース結果用の構造化データにクエリを実行することによって適切なレスポンスが返されます。以下の例のようなクエリが動的に構築されて、関連する BigQuery テーブルに対して実行されます。クエリは、リクエストどおりにドライバーの名前を返し、そのレスポンスがフロントエンドに返されます。
SELECT drivername FROM race_data WHERE season = 4 AND racename = 'Rome' AND session = "ses_v-race" AND pos = 1
Vertex AI Search は Google Cloud が提供する生成 AI で、構造化データソース、非構造化データソース、またはウェブサイトベースのデータソースの指定したコーパスに対して Google 検索のようなエクスペリエンスを実現します。
フォーミュラ E は、フォーミュラ E の概要、サステナビリティに対する取り組み、過去、現在、次世代のレースカーに関する情報など、さまざまなトピックを網羅した幅広い非構造化情報を Vertex AI Search に追加しました。バックエンド サービスは質問を受け取ると、その質問を Vertex AI Search にまず渡すかどうかを判断し、Vertex AI Search に、非構造化データ コーパスから最も関連性の高い情報を返すように依頼します。
Vertex AI Search からコンテキスト リッチな追加情報を取得したら、元の質問と合わせて、その情報が基盤モデルに送信されます。そうすることで、フォーミュラ E のコンテキストを追加した汎用 PaLM 2 モデルを実現しており、より具体的で関連性の高いレスポンスを構築してから、回答をフロントエンドに返します。
次の図は、バックエンドの全体的な動作を視覚的に表現したものです。

結果と考察
このシステムは小規模なチームがわずか 2 週間足らずで開発しました。2023 年チャンピオンシップ シーズンの最終レースが行われた週末には、フォーミュラ E だけでなく幅広いトピックに関する 700 件以上の質問に回答しました。フォーミュラ E のファンになったばかりの人からの初歩的な質問にも、レースカーの世代ごとのビルド変更に関する判断といった細かいニッチな情報を調べている長年のファンにも、運転中のレースカーの挙動を把握したいドライバーにも対応しました。
一般に、ユーザーは単純な質問から始めて、徐々に複雑な質問を尋ねるようになります。そのため、モデルの基盤トレーニング セットや、フォーミュラ E から提供された構造化データと非構造化データの非公開コーパスにわたる、利用可能なありとあらゆる範囲の情報から回答を引き出す必要がありました。
フォーミュラ E の CTO を務める Eric Ernst 氏は次のように述べています。「生成 AI [自然言語処理] インターフェースはデータの使い方と解釈の仕方に革命を起こすでしょう。どのような質問でも受け付け、ルート ソースの利用可能なすべてのデータを使って質問を調査し、最も関連性の高い結果を返す汎用 NLP インターフェースがあれば、ドライバーはこれまでアクセスできなかった分析情報に柔軟にアクセスできるようになり、詳しいファンもそうでないファンもフォーミュラ E の世界にひき込むことができます。」
LLM と生成 AI テクノロジーによって、情報にアクセスする新たな手段がもたらされました。この記事で紹介したシステムはテキストベースの出力を提供するものですが、マルチモーダル モデルが主流になるにつれて、画像やグラフ、動画などの動的に生成されたその他のタイプのメディアが使用されるようになり、レスポンスがますますリッチになるでしょう。
-新トレンド / 新技術、カスタマー エンジニアリング Sam Weeks
-フォーミュラ E、CTO Eric Ernst 氏