

Bitly のお客様は、地元の中学校から Fortune 500 のほとんどの企業まで多岐にわたり、そのユースケースには思い浮かぶ限りのあらゆるものが存在します。当社が通常 1 日に処理するリンククリック数と QR コードスキャン数は約 3 億 6,000 に及び、35 万人を超えるユニーク ユーザーによる 600~700 万のリンクや QR コードの作成をサポートしています。
プラットフォームの中心には、システムの約 400 億(さらに増加中)の有効なリンクを集めた、主要な 3 つのデータセットで構成されるリンクデータがあります。このデータは長年、手動でシャーディングされるセルフマネージド MySQL データベースに保存されていました。これまで、この仕組みは十分に機能していましたが、未来に向かって成長して行くにはいくつかの課題がありました。
MySQL: 課題と成長に伴う困難
第一に、データベースの可用性 100% を維持しながら、ソフトウェアやセキュリティのアップグレード、データベース ホストのプロビジョニングといった運用アクションを行うことは、控えめに言っても困難なものでした。
また、バックアップと復元プロセスはどちらも費用と時間がかかります。増大するデータセットの日次バックアップには、ほぼ丸一日かかりました。仮にデータセット全体を復元する必要が生じた場合は、少なくとも 2 人がかりで数日間作業することになるのは間違いありません。幸いにもこれまでそのような事態にはなっていませんが、楽しい作業ではなさそうです。
MySQL の手動シャーディングは物理シャードと論理シャード間での鍵配布に適していますが、メンテナンスに手間がかかります。変更を加えるとエラーが生じやすいため、シャーディング構成には触れないようにしていました。将来的なシャーディングの割り当てを考慮しても、この方法には限界があることがわかりました。
最終的にマルチリージョンとグローバル配信に目を向けたときに、手動でシャーディングする MySQL は、特に地理的分散を処理してくれるマネージド サービスの利便性と比べて、大きな障害になることが判明したのです。
私たちは、データの未来や会社の展開目標を達成するための最善策について考え、更新が不可欠であるという結論に達しました。成長と信頼性の向上を重視した設計のシステムが必要です。レプリケーションとスケーリングの機能が組み込まれていれば理想的でしょう。調査の結果、私たちは Google Cloud のエンタープライズ グレード NoSQL データベース サービスである Cloud Bigtable に行きつきました。
Bitly リンクの概要
Bigtable への移行について説明する前に、リンク管理システムの基本を理解しておきましょう。ユーザーが Bitly を使って長い URL を短縮すると、API レイヤを介して情報がバックエンドのデータストアに保存されます。この情報は、Bitly の短縮リンクと適切なルーティングのための対応する宛先リンクなどのメタデータで構成されます。ユーザーが Bitly の短縮リンクをクリックすると、同じバックエンド データストアに対してリクエストのリダイレクト先に関するクエリが実行されます。この基本フローにはカスタム back-half などの Bitly リンク オプションも含まれ、Bitly リンク管理プラットフォームの基軸となっています。
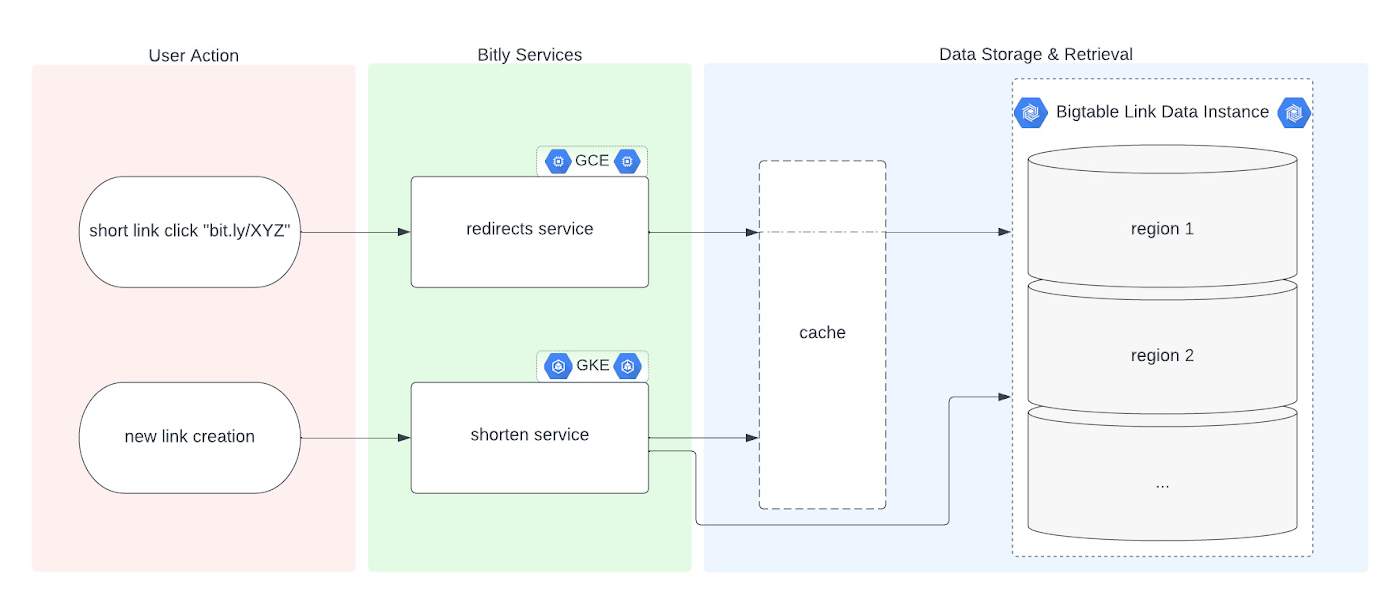
Bitly リンク管理プラットフォーム
なぜ Bigtable なのか
前述のように、私たちは解決方法を調査して、当社のニーズに最も適しているのは Bigtable であると判断しました。我々が求めていた次のような特徴を備えていたからです。
- 99.999% の SLA
- 無制限のスケーリング
- ミリ秒単位のレイテンシ
- 組み込みのモニタリング システム
- マルチリージョン レプリケーション
- リージョン間でのシームレスなデータ レプリケーションと低レイテンシを可能にする地理的分散
- コンピューティング リソースとストレージをユーザー トラフィックに合わせて調整し、必要に応じたシステムの成長とスケーリングを可能にするオンデマンド スケーリング
- 当社の一般的なアーキテクチャ(データベースを操作する API など、システムのさまざまな要素に Google Cloud サービスを使用)とのシームレスなインテグレーション
- リレーショナル セマンティクスを必要としない NoSQL データベース(移行するデータセットがアプリケーションの 1 つの主キーにインデックス登録される)
移行の実施
移行の対象としたのは、3 つの主要なセルフマネージド データセットです。サイズの大きい 2 つは、シャーディングされたデータベース アーキテクチャに編成されていました。移行に向けて最初に行ったのは、新しい Bigtable データベースの準備です。私たちは、スキーマ設計プロセスを繰り返し、Bigtable の徹底したパフォーマンス分析を行って、移行中も移行後もユーザー エクスペリエンスが中断されないことを確認しました。その後、Bigtable とのシームレスなインテグレーションとやり取りを実現するために、アプリケーション コードを微調整しました。最後に、移行後の堅牢な障害復旧プロセスを実装して、潜在的リスクを最小限に抑えました。
実際の移行中は、アプリケーションで「二重書き込み」フェーズを開始できるようにしました。これで、新しいリンクデータが既存の MySQL と新しい Bigtable テーブルの両方に同時に書き込まれます。Bigtable インスタンスへのデータの書き込みが始まった時点で、移行スクリプトを実行しました。Go スクリプトを使用し、既存の MySQL データセットをそれぞれ確認して各行を Bigtable に挿入します。これにより、古い情報をクリーンアップして、古いレコードを新しいフィールド データでバックフィルすることができました。
移行途中での不要なデータのクリーンアップ
実際、移行プロセス中に空き容量をかなり増やすことができました。Bitly プラットフォームの初期機能を廃止したことで、MySQL に保存されていた全データの半分弱を Bigtable への移行から除外できました。完全にクリーンなデータセットを作成して、移行中に不要な行を簡単にスキップすることができたのです。
以上で、移行プロセスで 800 億の MySQL 行が処理され、400 億件を少し超えるレコードが Bigtable に格納されました。26 TB のデータセット(レプリケーションを含まない)で Bigtable の利用を開始したことになります。少数のマシンで一連の Go スクリプトを同時に実行することで、私たちは、この移行プロジェクトを 6 日間で完了することができました(Go はほぼ問題なく機能しました)。
周到に準備する – 移行前の検証
次はデータの検証とカットオーバー期間です。ロールバックが必要になったときの予防措置として、Bigtable からデータが返されるようになっても MySQL への書き込みを継続します。
検証プロセスを詳しく調べる過程で MySQL と Bigtable の間でデータを比較すると、リンクがクリックされたり作成されたりするたびに不一致が生じていることがわかりました。すべてのレスポンスが安定したことを確認してから、数パーセント単位でカットオーバー プロセスを進め、すべての読み取りと書き込みが Bigtable で 100% 行われるようになるまで徐々にロールアウトしました。移行期間が順調に終了したら、二重書き込みを完全に無効にして、最終的に主軸の MySQL ホストを廃止します。
Google が Bitly をバックアップ
データは当社のライフラインです。確実に保護するためにできることは何でもします。私たちは、Bigtable バックアップと、真の障害復旧用にデータのコピーを Bigtable 外部に保持するプロセスの両方を使用して、冗長性計画をまとめました。
防御の最前線として、必要に応じてバックアップの Bigtable データセットに切り替えます。それだけでなく、インスタンスの障害やデータの破損、1 つ以上のテーブルをバックアップから復元する必要が生じるその他のデータ障害から保護するために、さらに 2 つの防御レイヤを実装しています。
このプロセスを行うために、まずはテーブルのBigtableバックアップを毎日作成し、一定日数保存します。次に、Bigtable から Cloud Storage にデータをエクスポートする Dataflow ジョブを約 1 週間ごとに実行します。必要があれば、 Dataflow を使用して、Cloud Storage から新しい Bigtable テーブルにデータを再インポートすることもできます。
Bigtable から Cloud Storage にエクスポートする Dataflow ジョブの実行では、1 秒間に平均 700~800 万行、時には 1 秒あたり 1,500 万行を読み取る高速エクスポートが行われます。その一方で、当社のサービスによる読み取りと書き込みは中断することなく続いています。また、Cloud Storage と Bigtable 間の復元ジョブ、インスタンスのスケーリングとともに増大する書き込み速度をリージョンのノード割り当ての上限でテストした結果、新しいテーブルへの書き込みは 1 秒あたり平均 200 万行弱でした。
長期的に使える短縮 URL
前述のように、当社が Bigtable を選んだのは技術要件と運用ニーズが満たされたからだけではありません。Bigtable なら将来の成長にも対応できるからです。時間の経過とともにシームレスにスケールする能力と、同時にシステムの可用性 SLA も改善できる点が、大きな決め手になりました。
5 倍、10 倍と規模が拡大するにつれ、それに合わせてデータ バックボーンを大きくして、お客様に提供する SLA を安定させる、さらには誰もが欲しがる「9」を 1 つ増やすことが急務です。当社には今後数年の大きな計画があります。Bigtable がその達成に貢献してくれることでしょう。
詳細については、Bigtable の評価から最終的な導入までがわかる以下のリソースをご覧ください。
- Bigtable のスキーマ設計が自社のリレーショナル データベースとアプリケーション ワークロードに適しているか評価する
- 必要なリージョンの組み合わせで Bigtable レプリケーションを使用し、可用性を高めてデータを世界中に分散する方法
- Bigtable のバックアップ、Bigtable Dataflow テンプレートを使用したデータのインポートとエクスポート
参考: 当社がデータを移行した具体的な方法については、今年の 9 月にサンディエゴで開催される GopherCon 2023 で詳しくご説明します。
– Bitly、シニア ソフトウェア エンジニア Zoe McCormick 氏





