

利用しているサービス:
Dataproc、Cloud Composer、BigQuery、Vertex AI、Cloud Source Repositories、Cloud Build など
コスト削減と処理速度向上を目的に Google Cloud を採用
パーソルキャリアの事業の中核ブランドである転職サービス「doda」は、主に「求人広告サービス」、「スカウトサービス」、「人材紹介サービス(以下、エージェントサービス)」などさまざまなサービスを提供しています。うち、「エージェントサービス」は、業種・職種ごとに専任のキャリアアドバイザー、法人営業担当が介在して転職希望者のニーズにあわせた求人紹介や転職・採用支援を行うというものです。
1 か月に発生する新規求人案件は数万件以上、doda が保有する求人情報は非公開案件を含め約 23 万件以上(2023 年 5 月時点)という規模の中で、キャリアアドバイザーや法人営業担当が適切な求人を転職希望者に迅速に届けなければなりません。そこで 2008 年から、新規求人をスピーディーに自動で紹介する機能、通称「セカンドマッチ」が実装されました。
「セカンドマッチ」とは、勤務地や年収、希望職種など、キャリアアドバイザーが転職希望者からヒアリングした情報を検索条件に指定することで、新たに登録された求人情報の中から希望に沿った求人情報が自動的にスピーディーに紹介される機械学習機能です。
2020 年には、インフラ環境がオンプレミスからクラウドに移行されるとともに、キャリアアドバイザーが指定した検索条件に合致した中でも、特にマッチング精度の高い情報だけを、適切な量で転職希望者に提供する機能改善も行われ、より迅速かつ適切な求人紹介を実現させてきました。
しかしその後の運用を経て、また同時に、コロナ禍で低迷していた求人数の復調や転職活動の活発化、これ伴い増え続けるデータ量を受け、新たな課題も見えてきたと、エージェント事業本部 執行役員の大浦征也氏(部署・役職名はインタビュー当時 ※)は話します。

「課題の 1 つはマッチングの精度です。マッチングには正解がなく、何をもって精度が高いとするかにはさまざまな視点が存在します。私たちはまず “人” の介在価値を第一に据えた上で、それをサポートするための AI を通じたマッチングの高度化が必要だと考えています。応募動機や思考プロセスは転職希望者様によって違うので、われわれの強みでもある “ワンブランドで豊富なチャネル” のデータを統合し、ユーザー体験をテクノロジーに生かすことが重要になってくるわけです。データに基づく AI の提案とインフォーマルな人の感覚はどちらも大事で、人と AI がタッグを組むことで、意味付けや納得感などの価値を向上できる仕組みを目指してます。」
そこで従前の環境から Google Cloud への移行を決定。その理由を春日氏は、次のように振り返ります。

「分散処理環境のモダン化には Dataproc が有効でした。また今後、機械学習のフレキシビリティを高めるため、MLOps による運用を考えたときに、Vertex AI が有効になると考えました。さらに分析環境では、BigQuery のコスト面、Looker などの BI ツールが使える将来性などを評価しました。個人情報を取り扱っているので、日本リージョンでの運用が可能だったことも Google Cloud 採用を後押ししました。このような大規模な移行はいままでなかったのですが、基幹サービスの主要部分を、肝を据えて変えていくというチャレンジができるのは、エンジニアに寛大で自由度の高い企業文化が背景にあるように感じています。」
TCO 1 か月あたり約 60% 削減、移行作業は内製化を実現
「セカンドマッチ」の移行では、分散処理用のフレームワークに Dataproc、データワークフロー オーケストレーション サービスとして Cloud Composer、データ分析用に BigQuery、MLOps に Vertex AI などが利用されています。また、Git リポジトリとして Cloud Source Repositories、CI / CD プラットフォームとして Cloud Build なども利用されています。CI / CD プラットフォームは、開発環境、ステージング環境、本番環境をどのような構成にするか、いかに運用していくか、システム全体を俯瞰しながら構築されています。
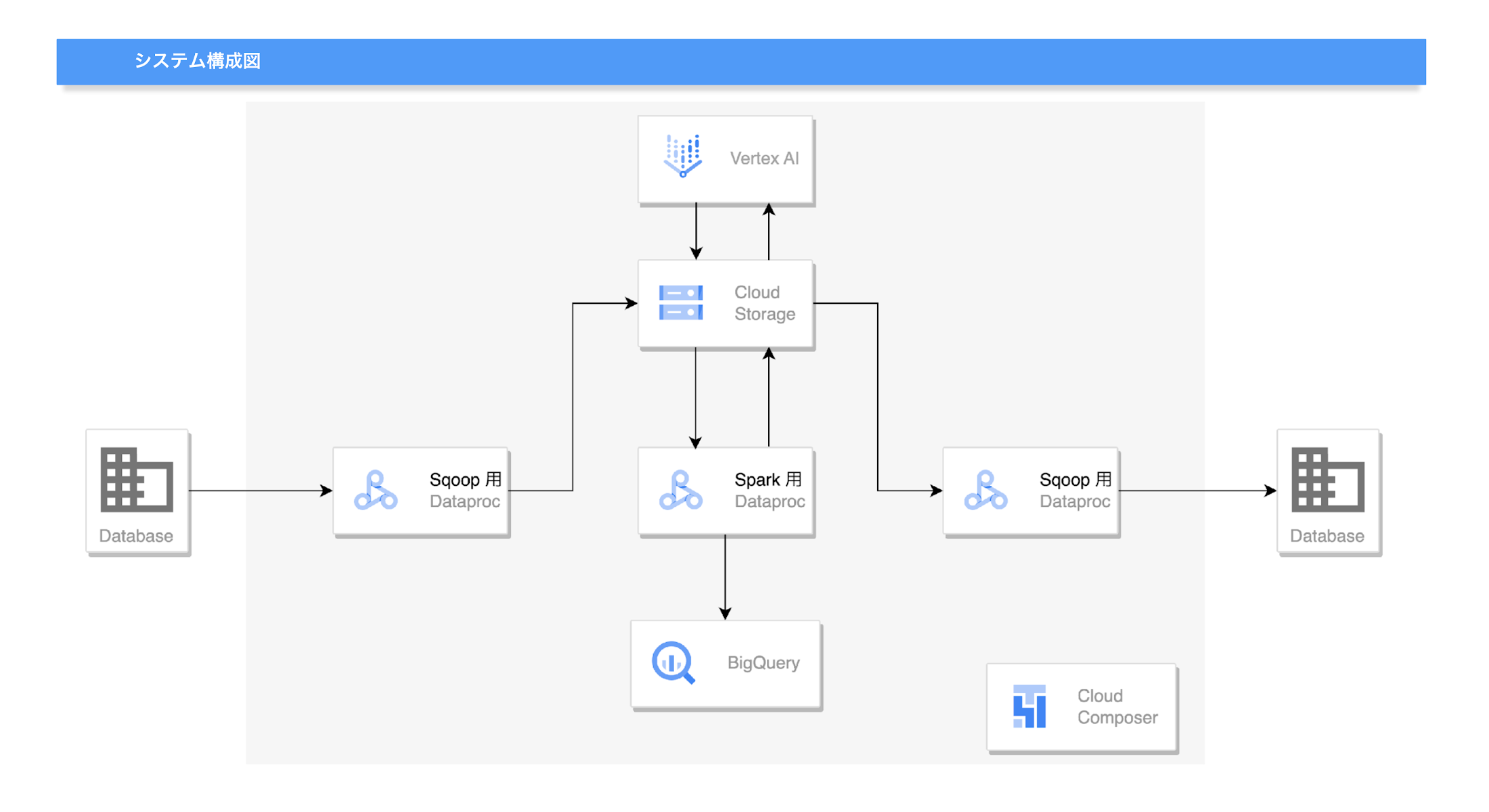
「まずは、データ処理時間が大幅に高速化され、ギリギリだった朝と夕方 2 回のデータ配信が安心して実行できるようになりました。景気回復の流れもあって求人も増え続けていますが、これに伴って増加し続けるデータ量・処理数にも十分耐えられています。また、クラウド サービスの TCO(総保有コスト)については、 1 か月あたり約 60% 削減という結果がでています。事業側にとっても非常に重要な仕組みであるセカンドマッチで大幅なコスト削減ができたことは、ビジネス面でも大きなインパクトがありました。そしてこの移行を内製で実施できたことも、今後さらなる内製化を目指す中で意味深いと感じています。」
一方、システム面での効果を春日氏は、「以前の Spark クラスタは実行可能になるまで 10 分程度かかっていましたが、Dataproc に移行後は約 90 秒で起動できます。BigQuery は 1 PB クラスのデータ量でも高速に分析できるので、コスト パフォーマンスが非常に高いと感じています。さらに Cloud Composer で、バッチ処理の可視化や再稼働などが容易になり、運用の負荷も大幅に削減できました」と話します。

また、テクノロジー本部 デジタルテクノロジー統括部 デジタルソリューション部 サーバーサイド・インフラエンジニアグループ シニアエンジニア 藤瀬聡一郎氏からは、「想定外の効果として加えるなら、Cloud Storage の高速なデータの読み書きには驚きました。セカンドマッチでは、1 回のデータ処理で約 500 GB の処理が可能、また 1 年分のデータの移行作業では、1 日分のデータコピーに 1 日かかっていたところが、2~3 時間で完了します。」
今後は機械学習のさらなるモダン化や ML Ops の強化などを計画
パーソルキャリアでは、「セカンドマッチ」の Google Cloud への移行完了を受けて、今後は Vertex AI による機械学習のさらなるモダン化や MLOps の強化などを計画しています。また Dataproc を利用することで、基幹システムから必要なデータを抽出し、加工・変換して、BigQuery に取り込む ETL(Extract: 抽出、Transform: 変換、Load: 書き出し)システムの構築も検討しているとのこと。

今後の取り組みについて寺本氏は、「転職希望者様が自分に合った求人に出会う確率をさらに高めることと、またそのあとの書類選考を通過する精度の向上を実現する仕組みを検討しています。たとえば、転職希望者様にとって、すべての希望が叶うとしても合格難易度の高い求人ばかりだったり、逆に合格難易度は高くなくても希望が叶いにくい求人ばかりだったら、自分らしく “はたらく” を実現する転職活動にはつながりません。そのバランスに挑戦し続けなければならず、事業側と技術側がより深く会話をしながら、どこを目指していくかを明確にしていくことが必要です。そのために Google Cloud とは、テクニカル面だけでなく、新しい仕組みづくりなどについても一緒に会話していきたいと思っています」と話します。






